군집화의 이해 (1)
군집화는 기계학습에서 비지도 학습의 한 유형으로, 데이터 포인트들을 비슷한 특성을 가진 그룹으로 나누는 작업입니다. 이번 글에서는 군집화의 개요, 계층적 군집화와 분리형 군집화, K-평균 군집화에 대해 알아보겠습니다.
군집화의 개요
군집화(Clustering) : 군집화는 주어진 데이터 세트를 유사한 데이터 포인트의 그룹(군집)으로 분할하는 과정입니다. 각 군집은 데이터 포인트의 집합으로, 군집 내의 데이터는 서로 유사하고, 다른 군집의 데이터와는 상이한 특징을 가집니다.
목적
- 데이터 구조 발견 : 데이터의 자연스러운 그룹을 식별하여 데이터의 구조를 이해합니다.
- 차원 축소 : 고차원 데이터를 요약하여 간결한 표현을 제공합니다.
- 이상 탐지 : 비정상적이거나 이상한 데이터 포인트를 식별합니다.
적용 사례
- 고객 세분화 : 고객 데이터를 기반으로 마케팅 전략을 세우기 위해 고객을 그룹화합니다.
- 이미지 분할 : 이미지의 픽셀을 군집화하여 유사한 영역을 식별합니다.
- 문서 분류 : 문서 데이터를 주제별로 그룹화합니다.
계층적 군집화와 분리형 군집화
군집화 알고리즘은 크게 두 가지 유형으로 나눌 수 있습니다 : 계층적 군집화와 분리형 군집화.
계층적 군집화
계층적 군집화(Hierarchical Clustering) : 계층적 군집화는 데이터 포인트 간의 계층적 관계를 기반으로 군집을 형성합니다. 주로 덴드로그램(dendrogram)을 사용하여 시각화합니다.
방법
- 병합적 군집화(Agglomerative Clustering)
- 각 데이터 포인트를 하나의 군집으로 시작하고, 가장 유사한 군집을 반복적으로 병합합니다.
- 완전히 병합될 때까지 계속 진행합니다.
- 분할적 군집화(Divisive Clustering)
- 전체 데이터를 하나의 군집으로 시작하고, 반복적으로 가장 비유사한 군집을 분할합니다.
- 원하는 군집 수에 도달할 때까지 계속 진행합니다.
장점
- 직관적 : 덴드로그램을 통해 데이터의 군집 관계를 쉽게 이해할 수 있습니다.
- 군집 수 필요 없음 : 사전에 군집 수를 지정할 필요가 없습니다.
단점
- 높은 계산 비용 : 큰 데이터 세트에서 느릴 수 있습니다.
- 유연성 부족 : 데이터 포인트가 한 번 잘못 군집화되면 수정이 어렵습니다.
분리형 군집화
분리형 군집화(Partitional Clustering) : 분리형 군집화는 데이터 포인트를 특정 기준에 따라 사전에 정의된 수의 군집으로 나누는 방법입니다.
대표 알고리즘
- K-평균 군집화(K-Means Clustering) : 가장 널리 사용되는 분리형 군집화 알고리즘 중 하나입니다.
K-평균 군집화
K-평균 군집화 : K-평균 군집화는 데이터 포인트를 K개의 군집으로 나누는 알고리즘입니다. 각 군집은 중심점(centroid)을 가지고 있으며, 각 데이터 포인트는 가장 가까운 중심점에 할당됩니다.
작동 원리
- 초기화 : K개의 중심점을 무작위로 선택합니다.
- 할당 단계 : 각 데이터 포인트를 가장 가까운 중심점에 할당합니다.
- 업데이트 단계 : 각 군집의 중심점을 군집에 속한 데이터 포인트의 평균으로 업데이트합니다.
- 반복 : 할당 단계와 업데이트 단계를 중심점이 더 이상 변화하지 않을 때까지 반복합니다.
수식
거리 측정
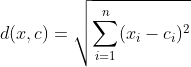
여기서 는 데이터 포인트, c 는 중심점입니다.
장점
- 효율성 : 대규모 데이터에서 빠르게 실행됩니다.
- 단순성 : 이해하고 구현하기 쉽습니다.
단점
- K 값 선택 : 적절한 K 값을 선택해야 합니다.
- 초기화 민감성 : 초기 중심점 선택에 따라 결과가 달라질 수 있습니다.
- 구형 군집 가정 : 군집이 구형이라고 가정하므로, 비구형 데이터에서는 잘 작동하지 않을 수 있습니다.
군집화의 이해 (2)
이어서 군집화의 두 번째 부분에서는 가우시안 혼합모델과 군집화 평가에 대해 알아보겠습니다.
가우시안 혼합모델
가우시안 혼합모델(Gaussian Mixture Model, GMM) : 가우시안 혼합모델은 데이터를 여러 개의 가우시안 분포의 조합으로 모델링하는 확률적 군집화 방법입니다. 각 데이터 포인트는 여러 가우시안 분포 중 하나에 속할 확률을 가집니다.
작동 원리
- 초기화 : K개의 가우시안 분포의 초기 파라미터(평균, 분산, 혼합 계수)를 설정합니다.
- 기대 단계(E-step) : 각 데이터 포인트가 각 가우시안 분포에 속할 확률을 계산합니다.
- 최대화 단계(M-step) : 계산된 확률을 기반으로 가우시안 분포의 파라미터를 업데이트합니다.
- 반복 : 기대 단계와 최대화 단계를 수렴할 때까지 반복합니다.
수식
혼합 가우시안 모델
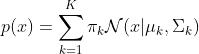
여기서
 : 혼합 계수
: 혼합 계수 : 가우시안 분포
: 가우시안 분포
장점
- 복잡한 군집 모델링 : 비구형 군집을 모델링할 수 있습니다.
- 확률적 해석 : 각 데이터 포인트의 군집 소속 확률을 제공합니다.
단점
- 초기화 민감성 : 초기 파라미터 설정에 따라 결과가 달라질 수 있습니다.
- 계산 복잡성 : 대규모 데이터에서 계산 비용이 높을 수 있습니다.
군집화 평가
군집화 평가의 목적은 모델의 성능을 측정하고, 최적의 군집 수를 선택하는 것입니다.
평가 지표
- 실루엣 계수(Silhouette Coefficient)
- 군집 내의 데이터 간 거리를 최소화하고, 군집 간의 거리를 최대화합니다.
- 값은 -1에서 1 사이이며, 1에 가까울수록 군집화가 잘된 것입니다.
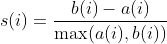
여기서
- a (i ) : 같은 군집 내의 다른 데이터 포인트와의 평균 거리
- b (i ) : 가장 가까운 다른 군집의 데이터 포인트와의 평균 거리
- 엘보 방법(Elbow Method)
- 군집 수에 따른 비용 함수(예 : SSE)의 변화를 관찰하여 최적의 군집 수를 결정합니다.
- 비용 함수의 급격한 변화가 완화되는 지점이 최적의 군집 수입니다.
- 내부 평가
- 군집 내의 응집도(cohesion)와 군집 간의 분리도(separation)를 측정하여 평가합니다.
- 예 : DB 인덱스(Davies-Bouldin Index)
- 외부 평가
- 사전에 정의된 레이블을 사용하여 군집화 결과를 평가합니다.
- 예 : 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수(F1 Score)
이 글에서는 군집화의 개요, 계층적 군집화와 분리형 군집화, K-평균 군집화, 가우시안 혼합모델, 그리고 군집화 평가에 대해 알아보았습니다. 군집화는 비지도 학습의 핵심 기법으로, 데이터의 구조를 이해하고, 유사한 데이터 포인트를 그룹화하는 데 유용합니다. 이러한 개념들을 잘 이해하고 활용하면 다양한 데이터 분석 및 처리 문제를 효과적으로 해결할 수 있습니다.
'인공지능학 > 기계학습' 카테고리의 다른 글
| [기계학습] 8. 의사결정트리의 이해 (1) | 2024.08.07 |
|---|---|
| [기계학습] 7. 서포트벡터머신의 이해 (0) | 2024.08.07 |
| [기계학습] 5. KNN 알고리즘과 로지스틱 회귀모델 (0) | 2024.08.05 |
| [기계학습] 4. 분류의 이해, Naïve Bayes (0) | 2024.08.01 |
| [기계학습] 3. 회귀분석의 이해, 선형회귀모델 (0) | 2024.07.31 |



